Automatic OCR with Textract and Python
Some of my colleagues from a non-developer department were in need for some help. They had to translate the product info from some images and it was very time consuming. If only there were a method to automatically extract the text from the images, to give them a head start...
One of the most accesibile solutions for OCR is to convert the image to a PDF and then use the text recognition feature of the PDF reader. Adobe Acrobat has it and if I recall correctly, so does Foxit. But if there are many images, getting each and everyone of them inside a PDF reader can be very cumbersome. If only there was a method to extract the text with a script...
When it comes to scripting, Python is my "go-to" language. I'm by no means an expert with it, I don't even dare to call myself a beginner, but it makes it really simple to achieve impressive results with a minimal knowledge of the language.
Textract is a Python package that makes OCR dead simple. After a somewhat lengthy installation, which took about half an hour for me (there aren't many steps, but it takes some time to install all the dependencies), I was able to extract the text from a given image with just a couple of lines of code.
import textract
text = textract.process('path/to/image.jpg')
fileName = file.open('path/to/image.txt', 'w')
fileName.write(text)
fileName.close()
In my case there were some issues regarding the language. The default english extraction is nice and dandy, but it had problems recongising the Romanian diacritics. But Textract uses the Tesseract OCR engine which, fortunately, has training data for a lot of other languages, including Romanian.
I have to admit, I had no idea how to add a new language to the Tesseract engine and the found instructions to retrain it seemed too complicated. There had to be a simpler way...
When in doubt, check the error messages. I just changed the language to Romanian and ran the script.
text = textract.process(
'path/to/image.jpg',
method='tesseract',
language='ron',
)
The execution error was actually very helpful it told me everything I needed to know. The ron.traineddata file that I had downloaded was missing from /usr/local/Cellar/tesseract/3.02.02_3/share/tessdata/ron.traineddata so I copied it there and that was it.
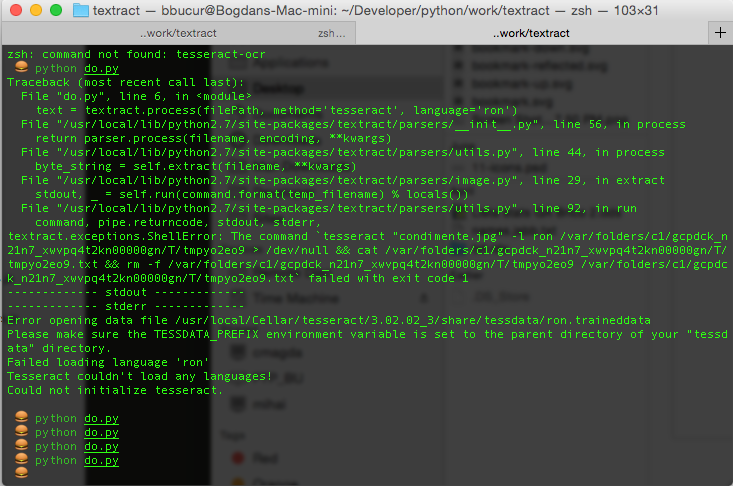
Even though the recognition is by no means perfect, it was a very fun and educational experience.
OCR is a very powerful tool for a programmer and even though you need a lot of detailed knowledge to fine tune it, you can also achieve impressive results with a small amount of time and close to no experience in the area. And Textract is one of the tools that makes it possible.